B站关键词视频信息爬虫(可直接运行)

在数字化时代,对于大量的视频分享网站如B站(哔哩哔哩),需要获取其内容信息进行数据分析、学术研究或是个人娱乐已经变得越来越普遍。这时,一个能够高效抓取所需视频信息的爬虫工具就显得尤为重要。今天我们就来学习如何编写一个B站关键词视频信息爬虫。
爬虫是一种自动获取网页内容的程序,它按照一定的规则,自动地抓取互联网信息。B站作为年轻人喜爱的视频内容分享平台,拥有丰富的视频资源和用户互动信息。通过关键字视频信息爬虫,我们可以获取特定主题或标签下的视频资源,这些数据可以用于内容分析、市场调研等各种用途。
准备工作
在开始编写爬虫之前,需要准备好以下工具和资源:
Python编程环境:因为Python的语法简洁且拥有丰富的网络爬虫库,是最适合编写爬虫的语言之一。
请求库:如`requests`库,用于发送HTTP请求。
解析库:如`BeautifulSoup`或`lxml`,用于解析网页内容。
伪装身份:由于爬虫会频繁对网站发起请求,有可能触发B站的反爬机制,因此需要设置合适的请求头(UserAgent等)来模拟正常的浏览器行为。
爬虫开发步骤
STEP1:环境搭建
首先确保已经安装Python环境,并通过pip安装必要的库:
```
pipinstallrequests
pipinstallbeautifulsoup4
```
STEP2:分析目标网页
打开B站,输入关键词进行搜索,观察搜索结果页面(SERP)的结构,特别是视频数据是如何加载和展示的。
STEP3:编写爬虫代码
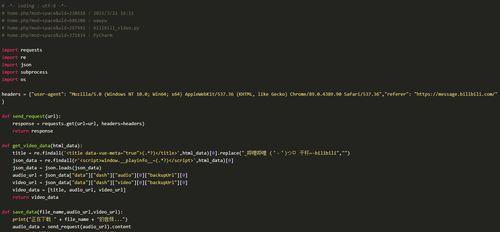
以Python为例,我们将编写一个简单的爬虫脚本,用于获取B站搜索结果页面的视频信息。以下是一个基础代码框架:
```python
importrequests
frombs4importBeautifulSoup
B站搜索结果页面URL
SEARCH_URL='https://search.bilibili.com/operate/web/suggest?keyword={}'
设置请求头
HEADERS={
'User-Agent':'Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/58.0.3029.110Safari/537.3'}
defget_bilibili_search_result(keyword):
准备请求参数
params={'keyword':keyword}
response=requests.get(SEARCH_URL.format(keyword),headers=HEADERS)
检查请求是否成功
ifresponse.status_code==200:
returnresponse.text
else:
return"请求失败,状态码:"+str(response.status_code)
defparse_html(html):
解析html,提取视频信息
soup=BeautifulSoup(html,'html.parser')
video_list=soup.find_all('div',class_='video-list-item-info')
forvideoinvideo_list:
video_title=video.find('a',class_='title').get('title')
print(video_title)
defmain():
html=get_bilibili_search_result(keyword)
parse_html(html)
if__name__=='__main__':
main()
```
STEP4:运行爬虫
在命令行中运行编写的爬虫脚本:`pythonscript_name.py`
STEP5:数据使用与处理
获取的数据可以进行清洗、存储、分析等进一步处理。将视频信息保存到CSV文件或数据库中,用于后续的数据分析工作。

注意事项
遵守法律法规:在进行网络爬取时,应遵守相关法律法规,尊重网站的robots.txt文件的规定。
减少对目标网站的负担:合理设置爬虫的请求间隔和频率,避免对目标网站造成过大压力。
异常处理和日志记录:在代码中添加异常处理机制以及日志记录,以便爬虫运行时出现问题能够快速定位和解决。
结语
通过以上步骤,你就能自主开发一个简单的B站关键词视频信息爬虫了。这个基础工具将为你的数据分析、内容聚合等工作带来便利。当然,实际操作中可能遇到各种细节问题,在实践中不断地解决问题,优化爬虫将是不断深化你对爬虫技术理解的过程。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 3561739510@qq.com 举报,一经查实,本站将立刻删除。!
本文链接:https://www.jumeiyy.com/article-5647-1.html
上一篇
B站视频流量分析目标受众








最新文章
-

剑魂游戏中发光字幕如何开启?开启发光字幕的步骤是什么?
2025-05-06 -
CF宠儿枪械垂直水平调整方法?
2025-05-06 -

三国杀移动版电脑端下载方法是什么?下载过程中需要注意什么?
2025-05-06 -

完美世界中技术暂停如何关闭?关闭方法是什么?
2025-05-06 -

cf好友积分需要多少点券?如何快速获得积分?
2025-05-06 -

地下城手游新角色爆料有哪些?新角色的技能特点是什么?
2025-05-06 -

三国杀张角的牌组搭配建议是什么?
2025-05-06 -

地下城任务中丘陵部分的完成方法是什么?
2025-05-06
热门文章
-
王者荣耀中嘎雅的正确路线是什么?如何快速到达?
2025-04-13 -

英雄联盟变紫色怎么办?游戏界面变色的原因及解决方法?
2025-04-13 -

魔兽世界中代码是如何使用的?
2025-04-14 -

魔兽世界中徐弥陀的打法是什么?有哪些策略可以采用?
2025-04-13 -

操刀妹的正确玩法是什么?如何在游戏中发挥其优势?
2025-04-14 -

英雄联盟鳄鱼国服上线时间是什么时候?
2025-04-14 -

魔兽健身蹦极游戏玩法是什么?有哪些技巧可以提高游戏体验?
2025-04-14 -
英雄联盟中英雄瞬移问题如何解决?
2025-04-14